

metadata
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
license: llama3.3
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- neuralmagic
- redhat
- speculators
- eagle3
Llama-3.3-70B-Instruct-speculator.eagle3
Model Overview
- Verifier: meta-llama/Llama-3.3-70B-Instruct
- Speculative Decoding Algorithm: EAGLE-3
- Model Architecture: Eagle3Speculator
- Release Date: 09/15/2025
- Version: 1.0
- Model Developers: RedHat
This is a speculator model designed for use with meta-llama/Llama-3.3-70B-Instruct, based on the EAGLE-3 speculative decoding algorithm.
It was trained using the speculators library on a combination of the Aeala/ShareGPT_Vicuna_unfiltered and the train_sft split of HuggingFaceH4/ultrachat_200k datasets.
This model should be used with the meta-llama/Llama-3.3-70B-Instruct chat template, specifically through the /chat/completions endpoint.
Use with vLLM
vllm serve meta-llama/Llama-3.3-70B-Instruct \
-tp 4 \
--speculative-config '{
"model": "RedHatAI/Llama-3.3-70B-Instruct-speculator.eagle3",
"num_speculative_tokens": 3,
"method": "eagle3"
}'
Evaluations
Use cases
| Use Case | Dataset | Number of Samples |
|---|---|---|
| Coding | HumanEval | 168 |
| Math Reasoning | gsm8k | 80 |
| Text Summarization | CNN/Daily Mail | 80 |
Acceptance lengths
| Use Case | k=1 | k=2 | k=3 | k=4 | k=5 | k=6 | k=7 |
|---|---|---|---|---|---|---|---|
| Coding | |||||||
| Math Reasoning | 1.80 | 2.44 | 2.89 | 3.15 | 3.33 | 3.44 | 3.52 |
| Text Summarization | 1.72 | 2.21 | 2.53 | 2.74 | 2.86 | 2.93 | 2.98 |
Performance benchmarking (4xA100)
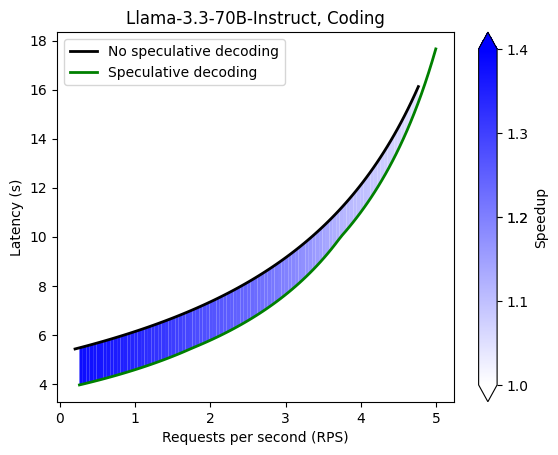

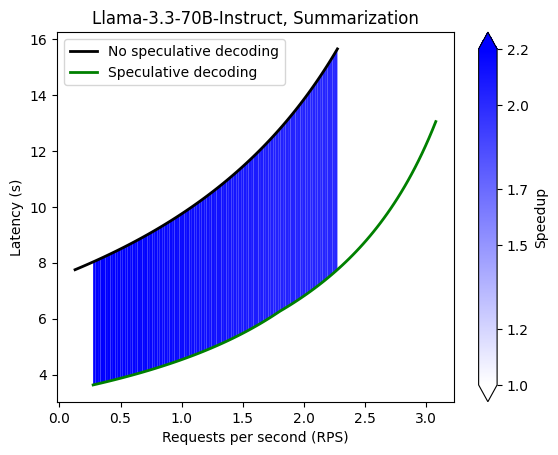
Details
Configuration- temperature: 0
- repetitions: 5
- time per experiment: 4min
- hardware: 4xA100
- vLLM version: 0.11.0
- GuideLLM version: 0.3.0
Command
GUIDELLM__PREFERRED_ROUTE="chat_completions" \
guidellm benchmark \
--target "http://localhost:8000/v1" \
--data "RedHatAI/SpeculativeDecoding" \
--rate-type sweep \
--max-seconds 240 \
--output-path "Llama-3.3-70B-Instruct-HumanEval.json" \
--backend-args '{"extra_body": {"chat_completions": {"temperature": 0.0}}}'
</details>