Submitted by Cardlnal 192 DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards · 3 authors 6 1
Submitted by xiaochonglinghu 167 TransitLM: A Large-Scale Dataset and Benchmark for Map-Free Transit Route Generation AMAP-ML 112 2
Submitted by Ukpkmkkk 162 Perception or Prejudice: Can MLLMs Go Beyond First Impressions of Personality? The University of Tokyo 10 1
Submitted by zzzhr97 91 π-Bench: Evaluating Proactive Personal Assistant Agents in Long-Horizon Workflows Simplified Reasoning 35 3
Submitted by zykRichard 85 Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps RTP-LLM 1
Submitted by groundhogLLM 56 ACC: Compiling Agent Trajectories for Long-Context Training University of Science and Technology of China 1
Submitted by Ziqi 46 PhysX-Omni: Unified Simulation-Ready Physical 3D Generation for Rigid, Deformable, and Articulated Objects · 8 authors 95 1
Submitted by zbhpku 40 LatentOmni: Rethinking Omni-Modal Understanding via Unified Audio-Visual Latent Reasoning Kling Team 10 1
Submitted by Nova2001 35 SEGA: Spectral-Energy Guided Attention for Resolution Extrapolation in Diffusion Transformers University of Toronto Computer Science 3
Submitted by SeanWu25 34 Forecasting Scientific Progress with Artificial Intelligence University of Oxford 20 1
Submitted by YJ-142150 33 WorldKV: Efficient World Memory with World Retrieval and Compression KAIST AI 1
Submitted by taesiri 33 Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning University of Illinois at Urbana-Champaign 11 3
Submitted by Zuica96 24 SpaceDG: Benchmarking Spatial Intelligence under Visual Degradation Visionary-Laboratoary 26 1
Submitted by jiahaoplus 24 Sensor2Sensor: Cross-Embodiment Sensor Conversion for Autonomous Driving Google 2
Submitted by jhpark96 24 FlowLong: Inference-time Long Video Generation via Manifold-constrained Tweedie Matching KAIST AI 8 1
Submitted by taesiri 22 Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention NVIDIA 124 1
Submitted by ttu1818 19 Q-ARVD: Quantizing Autoregressive Video Diffusion Models National University of Singapore 16 2
Submitted by Jinyang23 18 Maestro: Reinforcement Learning to Orchestrate Hierarchical Model-Skill Ensembles · 10 authors 14 1
Submitted by Johnson0213 16 AutoRubric-T2I: Robust Rule-Based Reward Model for Text-to-Image Alignment Arena 3 1
Submitted by Bturtel 14 Training Large Language Models to Predict Clinical Events Lightning Rod Labs 2
Submitted by Ephemeral182 10 GenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation MeiGen-AI 32 2
Submitted by arkilpatel 10 Forecasting Downstream Performance of LLMs With Proxy Metrics McGill NLP Group 6 1
Submitted by CapitalLiu 10 KVServe: Service-Aware KV Cache Compression for Communication-Efficient Disaggregated LLM Serving Institute of Computing Technology, Chinese Academy of Sciences 8 2
Submitted by Chtholly17 9 ClinSeekAgent: Automating Multimodal Evidence Seeking for Agentic Clinical Reasoning UCSC-VLAA 14 2
Submitted by Master-Shi 8 One Sentence, One Drama: Personalized Short-Form Drama Generation via Multi-Agent Systems Nanyang Technological University 1
Submitted by dahyekim 8 Swift Sampling: Selecting Temporal Surprises via Taylor Series Boston University 1
Submitted by mingkaid 7 Efficient Agentic Reasoning Through Self-Regulated Simulative Planning SAILING Lab (CMU & MBZUAI) 2 1
Submitted by jhcho99 6 SceneAligner: 3D-Grounded Floorplan Localization in the Wild Cornell University 7 1
Submitted by beomjin-ahn 6 LoREnc: Low-Rank Encryption for Securing Foundation Models and LoRA Adapters Samsung Research 2
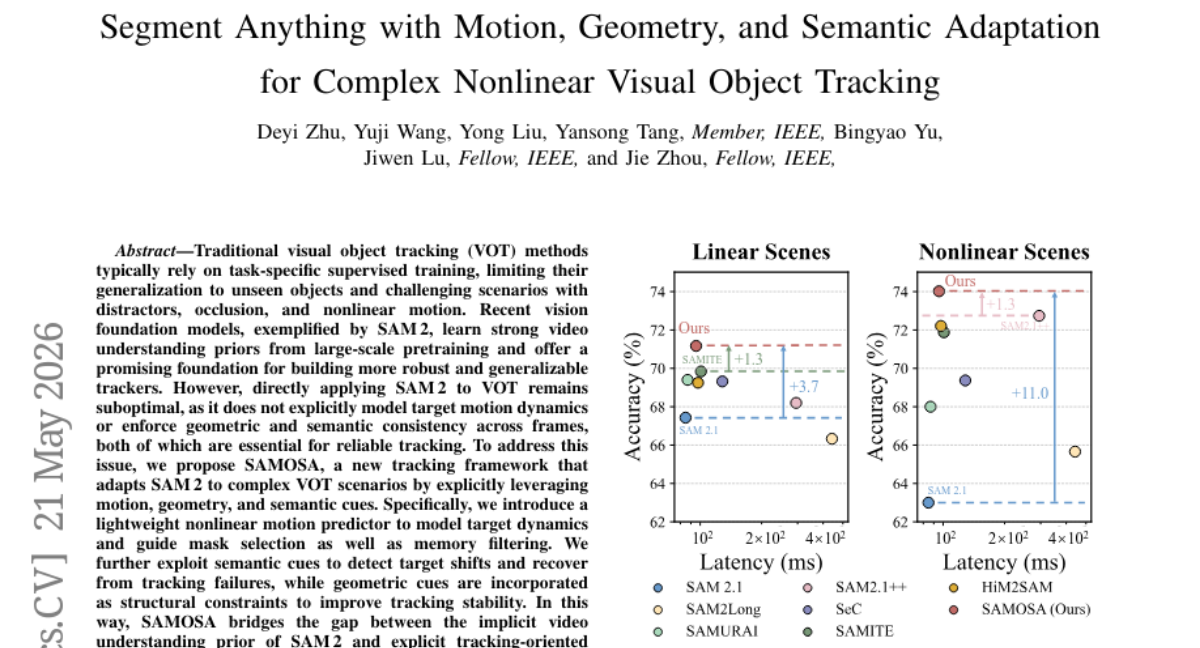
Submitted by VoyageWang 5 Segment Anything with Motion, Geometry, and Semantic Adaptation for Complex Nonlinear Visual Object Tracking Tsinghua University 5 1
Submitted by jusjinuk 5 Rule2DRC: Benchmarking LLM Agents for DRC Script Synthesis with Execution-Guided Test Generation Seoul National University 1 2
Submitted by dora2023 4 Diversed Model Discovery via Structured Table Discovery University of Waterloo 1 1
Submitted by VictorYeste 3 More Context, Larger Models, or Moral Knowledge? A Systematic Study of Schwartz Value Detection in Political Texts · 2 authors 0 1
Submitted by EunsuKim 3 "I didn't Make the Micro Decisions": Measuring, Inducing, and Exposing Goal-Level AI Contributions in Collaboration · 4 authors 2 1
Submitted by xxayt 3 OmniPro: A Comprehensive Benchmark for Omni-Proactive Streaming Video Understanding · 7 authors 6 1
Submitted by ZacharyNovack 2 Live Music Diffusion Models: Efficient Fine-Tuning and Post-Training of Interactive Diffusion Music Generators · 11 authors 24 1
Submitted by Breezelled 2 AnyMo: Geometry-Aware Setup-Agnostic Modeling of Human Motion in the Wild CRUISE Research Group (UNSW) 0 1
Submitted by taesiri 2 From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning · 6 authors 1
Submitted by Songweii 2 DecQ: Detail-Condensing Queries for Enhanced Reconstruction and Generation in Representation Autoencoders · 6 authors 5 1
Submitted by nandan523 2 Same Architecture, Different Capacity: Optimizer-Induced Spectral Scaling Laws New York University 1
Submitted by pablomm 2 Platonic Representations in the Human Brain: Unsupervised Recovery of Universal Geometry Universitat de Barcelona 1 1
Submitted by wuyangchen 2 Lean Refactor: Multi-Objective Controllable Proof Optimization via Agentic Strategy Search · 7 authors 1
Submitted by luoxue-star 2 SAM 3D Animal: Promptable Animal 3D Reconstruction from Images in the Wild · 7 authors 2
Submitted by wdika 1 Disentangling Sampling from Training Budget in Class-Imbalanced CT Body Composition Segmentation · 3 authors 0 1
Submitted by HaokunWen - FashionLens: Toward Versatile Fashion Image Retrieval via Task-Adaptive Learning · 6 authors 1


 Cardlnal
Cardlnal